Okay, this is another one of those linux newbie posts where I tried to figure out how to do something that’s probably really obvious to all you seasoned hackers out there.
Anyway here I go clogging up the internet with a post that somebody, somewhere will hopefully find useful.
Are you that person? Well… have you ever used the shell command curl to fetch a web page? It’s cool, isn’t it, but you do end up with a splurge of ugly HTML tags in your terminal shell:

Eugh!
So… how about we parse that HTML into something human-readable?
Enter my new friend, w3m, the command-shell web browser!
If you’re using OS X, you can install w3m using darwinports thusly:
sudo port install w3mLinux hackers, I’m going to assume you can figure this out for yourselves. So, with a brand-new blade in our swiss-army knife, let’s pipe the curl command into the standard input for w3m and see what happens:
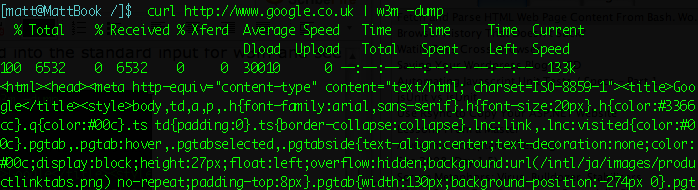
Hmm… two problems here: because I’ve grabbed its output and piped it off to w3m, curl has started blethering on about how long it took. I can fix that with swift but ruthless the flick of a -s switch to silence it. How about all that raw HTML though – I thought this w3m thing was supposed to parse my html, not just regurgitate it?
It turns out that w3m assumes its input is of MIME-type text/plain, unless told otherwise. Let’s set the record straight:

Aw yeah. Now we’re talking. Old-skool green-screen meets nu-school interweb. It’s like being back on the BBS network of yore.
What’s the point of all this? Well, that’s up to you. I have a couple of ideas, but you’re going to have to start coming up with your own you know. Why are you reading this anyway? Haven’t you got anything better to do?